
Merge dvou tabulek v Pythonu

Aktuálně studuju na Coursera kurz Introduction to Data Science in Python a jak se to někdy hezky sejde, naskytla se mi v práci možnost to rovnou použít v praxi.
Rozhodně nejde o nic světoborného — prostě potřebuju dát dohromady dvě tabulky, trochu pošolichat data a udělat hierarchický index. Asi by to šlo udělat i v něčem jiném a možná jednodušeji. Ale Python mám rád a je to zábava si trochu zablbnout.
Následující zápisek je zdokumentování postupu, který by se mi mohl někdy v budoucnu hodit. Pokud jste někdo větší borec v Pythonu — tj. nepíšete v něm jen jednou za pár let, jako já — budu rád, když mi poradíte nějaké zlepšení.
O co jde?
Určitě jste se s tím už setkali. Máte určitý nástroj, od kterého byste čekali celkem jednoduchou funkcionalitu a on ji, z nějakého důvodu, nemá. Takže skončíte u exportu dat a nějaké externí úpravy.
To je náš výchozí bod — máme dvě vyexportované tabulky, formát souboru v tomhle případě nehraje roli. Může to být CSV, Excel atd. Ty naše dvě vypadají takhle:
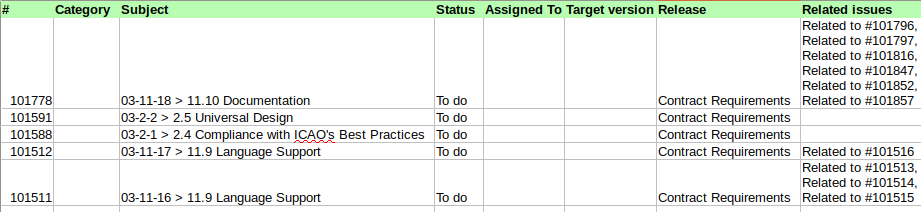
Tabulka CSD.csv
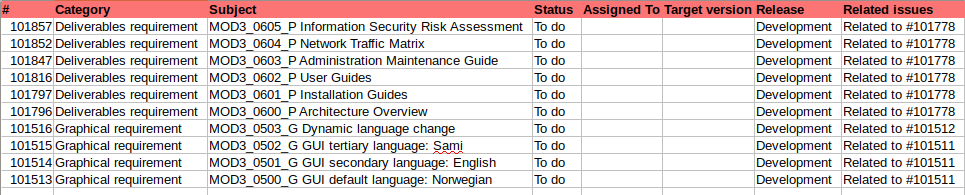
Tabulka RQS.csv
Co je pro nás podstatné, obě tabulky mají vzájemnou vazbu přes sloupec Related issues, který odkazuje na identifikátor záznamu v druhé tabulce (sloupec #). Co není na první pohled zřejmé, záznamy v tabulce CSD (zelené záhlaví) mají vazbu 1:N na záznamy v tabulce RQS (červené záhlaví). Pro úplnost, vazba je obousměrná, nás ale zajímá jen směr CSD -> RQS.
No a potřebovali bychom z toho dostat tabulku, která vypadá takto (barevné rozlišení je pro přehlednost, který data kam patřily):
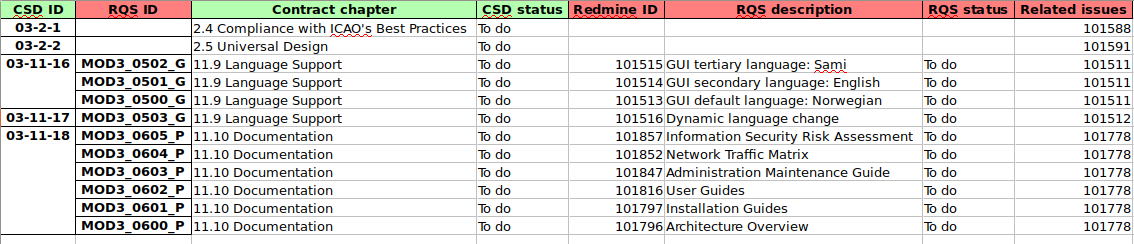
Výsledná tabulka matrix.xlsx
Povšimněte si v prvních dvou sloupcích hierarchického indexu (CSD ID, RQS ID), který vyjadřuje vazbu 1:N.
Jak na to?
To, kolem čeho se točí výše zmíněný kurz a co jsem pro manipulaci s tabulkami použil, je knihovna pandas — open source nástroj pro datové struktury a datovou analýzu. Na svých stránkách píšou, že je easy-to-use a opravdu se s tím pěkně pracuje.
Základním elementem v pandas je DataFrame, ekvivalent dvourozměrného pole (se spoustou vychytávek). První krok je, převést naše tabulky do DataFrame. pandas mají spoustu možností, jak načíst externí data, my použijeme metodu read_csv:
import pandas as pd
csd = pd.read_csv('CSD.csv')
rqs = pd.read_csv('RQS.csv')
Zpracovávaná tabulka může být rozsáhlá, co do počtu sloupců, a protože výpis DataFramu na konzoli se defaultně zalamuje, může se hodit příkaz pro vypnutí této možnosti:
pd.set_option('display.expand_frame_repr', False)
Data máme načtená, můžeme je začít upravovat. První na řadě je tabulka CSD. Potřebujeme udělat následující úpravy:
- Rozdělit data ze sloupce
Subjectdo dvou samostatných sloupců pomocí oddělovače>. - Smazat sloupce, které v cílové tabulce nepotřebujeme.
- Přejmenovat sloupce, aby v cílové tabulce dávali větší smysl.
csd[['CSD ID', 'Contract chapter']] = csd['Subject'].str.split(
' > ', expand=True)
csd.drop(['Category', 'Subject',
'Assigned To', 'Target version',
'Release', 'Related issues'], axis=1, inplace=True)
csd = csd.rename(columns={'Status': 'CSD status'})
Navíc uděláme jednu operaci, kterou budeme potřebovat později — přidáme si nový sloupec numeric ID, podle kterého cílovou tabulku později setřídíme.
csd['numeric ID'] = csd['CSD ID'].str.replace('-', '').map(int)
Obdobné úpravy uděláme na tabulce RQS a můžeme se pustit do spojování. pandas nabízejí metodu merge, která funguje obdobně jako SQL join.
matrix = csd.merge(rqs, left_on='#', right_on='Related issues', how='left')
Dalším krokem je vytvoření hierarchického indexu:
matrix.set_index(['CSD ID', 'RQS ID'], inplace=True)
Následně setřídíme novou tabulku podle sloupce numeric ID, který jsme si dočasně přidali v rámci úprav tabulky CSD. Sloupec po setřídění odstraníme. Smyslem téhle eskapády je setřídit tabulku numericky podle sloupce, kde jsou string hodnoty.
matrix = matrix.sort_values(by='numeric ID')
matrix.drop('numeric ID', axis=1, inplace=True)
Teď si ještě seřadíme sloupce, abychom se v cílové tabulce dobře orientovali:
cols = ['Contract chapter', 'CSD status',
'Redmine ID', 'RQS description',
'RQS status', 'Related issues']
matrix = matrix[cols]
A pozor! Finální příkaz… zapíšeme do Excelu, resp. jiného výstupního formátu. Máme hotovo.
matrix.to_excel('matrix.xlsx')
Kompletní skript
Celý skript je k dispozici na Bitbucketu jako snippet: matrix.py.
Jak nainstalovat pandas?
Nejjednodušší způsob, jak nainstalovat pandas a další spřízněné knihovny (třeba NumPy a dokonce i samotný Python) je package manager Miniconda. Stačí stáhnout instalátor pro váš operační systém a pak nainstalovat pandas příkazem:
conda install pandas