
Fluentd, budoucnost logování (část 1)

Dlouhá léta byl synonymem pro sbírání distribuovaných logů, tzv. ELK stack, (dnes nazývaný Elastic Stack), kdy ELK je akronym pro Elasticsearch, Logstash, Kibana. A je to framework věru letitý (což není samo o sobě na škodu). Bohužel, letitost sebou nese v IT jednu nepříjemnou věc — ukotvenost v čase a určitém kontextu.
Tím kontextem je v případě ELKu tehdy ještě převažující důraz na server-based architekturu, která se teprve zvolna začínala přesouvat do cloudu. Ta doba už je pryč… cloudová řešení jsou plně etablovaná a dnešní doba si žádá jiný přístup — více distribuovaný, více granulární, více autonomní.
To vše jsem si uvědomil, když jsme v práci začali pracovat na novém produktu (nativní cloudová (infrastrukturní) služba) a já jsem dostal na starost část logování. Ukázalo se, že jak proprietární logování, tak případné využití ELKu je pro můj případ nedostatečné až nepoužitelné. A tak jsem se ponořil do světa Fluentd.
Trocha historie
Když jsem začínal programovat, bylo to jednoduché — byla jedna aplikace, která logovala na jedno místo (teda, ehm, pokud vůbec logovala) a všechno bylo krásné, tráva zelenější atd.
Pak se začaly používat clustery. Pořád ještě relativně jednoduché: hlavní bylo nějak sehnat všechny logy po všech nodech a nějakým způsobem je pročesat. Starý dobrý grep 🤗
Už u clusterovaných řešení býval často problém, dohledat tok určité business logiky (některým vývojářům můžete opakovaně vtloukat do hlavy důležitost correlation ID, ale marně) a s rozvojem (distribuovaného) messagingu, SOAP web services a následně SOA, se to stávalo stále více komplikovanější a pracnější.
Tady přichází ke slovu ELK a na dlouhá léta nastaví nepsaný “industrial standard”. Pokud vás ELK minul, tady je krátké shrnutí:
- Logstash posbírá lokálně data v různých formátech, podle potřeby je volitelně transformuje a publikuje na cílovou platformu, kterou je většinou Elasticsearch, nicméně podobně jako u vstupů, existuje spousta výstupních pluginů.
- Elasticsearch data oindexuje a umožní je filtrovat, či analyzovat pomocí dotazovacího jazyka.
- Kibana pak výstupy z Elasticsearche graficky zobrazí.
Ale všechno jednou končí a cloud už klepe na dveře. A ne jenom cloud. Ale i Docker a Kubernetes. 🤯 Je potřeba to začít dělat trochu jinak.
Je Fluentd další generací logování?

Krátká odpověď je ano. Avšak musím upřesnit jednu věc — výše napsané může svádět k myšlence, že Fluentd je náhradou ELKu. Není to tak. Není to úplně přesné, ale Fluentd je spíše náhradou Logstashe (tedy jen části ELKu) a například Elasticsearch & Kibana můžou být použity společně s Fluentd v jednom řešení.
V tomhle článku nechci zmíněné technologie srovnávat (stačí zagooglovat), ale abych se z toho úplně nevyvlíkl, uvedu dva důvody, proč je Fluentd o kus dál v budoucnosti:
- Docker má vestavěný logging driver pro Fluentd.
- Fluentd, stejně jako Kubernetes jsou graduované projekty CNCF (Cloud Native Computing Foundation).
Samozřejmě, není žádná zásadní překážka, proč nepoužít ELK v Kubernetes. Ale Fluentd je prostě lepší “domain match” a netáhne za sebou historická (architekturní a jiná) rezidua.
Co je to Fluentd?
Fluentd is an open source data collector, which lets you unify the data collection and consumption for a better use and understanding of data.
U základů Fluentd je představa, že logy jsou primárně pro stroje. Logovací infrastruktury minulosti (viz historické okénko výše) byly designovány pro lidi. To v dnešní době geometricky rostoucího škálování a granularity serverless řešení není možné — lidé (vývojáři, DevOps atd.) vidí a analyzují pouze mikro-zlomek logů a metrik.
Jestliže máme data určená přednostně pro stroje, nabízí se několik osvědčených řešení. Fluentd si vybralo dnes všudypřítomný JSON, hlavně z toho důvodu, že i když JSON hůře performuje, nežli třeba binární formáty, tak na druhou stranu je JSON buď nativně, nebo jednoduše podporován na většině platforem z nichž Fluentd logy sbírá, nebo kam je publikuje. Navíc, JSON je dnes už standardním výstupem většiny zralých logovacích knihoven.
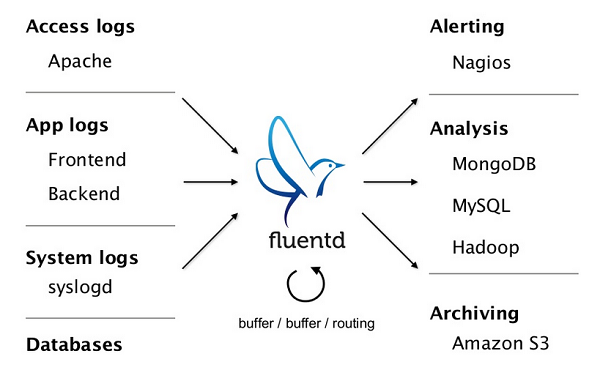
Zdroj: https://www.fluentd.org/
Pokud odhlédneme od datového formátu a podíváme se na zbytek Fluentd (pominu pokročilejší věci jako reliability apod.), jedná se vlastně o jednoduchý pipelines pattern, seskládaný ze spousty pluginů. Ještě jsem to neřekl? Fluentd je plugable. 🤓
- Data sbírají input pluginy, což jsou vlastně listenery, které naslouchají pro definované log events, nové logovací záznamy.
- Než data opustí Fluentd, můžou projít smečkou procesních pluginů:
- parser pluginy (JSON, regex, ad.),
- filter pluginy (grep 🤗, parser, ad.),
- buffer pluginy (memory, file),
- a ještě celou řadou dalších pluginů.
- Přechroustaná data se odešlou některým z output pluginů.
Příklad několika jednoduchých generických pipeline:
Input -> Output— nejjednoduší pipeline, data se načtou a odešlou, bez nějakého procesování.Input -> Filter -> Output— druhá nejjednodušší pipeline, data se mezi načtením a odesláním filtrují.Input -> Filter -> Parser -> Formatter -> Output— co k tomu dodat? 🤷♂️
Dobře, dobře, starý bobře, “plugable pipelines”. 🙄 Co nějaká killer feature? Ano, ano, Fluentd má ještě nějaké to eso v rukávu — data, která prochází skrz Fluentd tečou po tzv. routách, kdy lze pomocí labelů a tagů usměrňovat dráhu dat.
Tato feature sice může vypadat nenápadně, ve skutečnosti ale umožňuje, aby
se toky dat ve Fluentd rozdělovaly a spojovaly a taktéž zajišťuje, že mezi
všemi pluginy může být vztah M:N. Jinými slovy, můžu sbírat data z více
zdrojů a publikovat je do více cílů, ale zároveň přesně specifikovat, který
data kam půjdou a co se s nima v průběhy cesty stane. A to vše velmi přehledně
a jednoduše. 👍
Abychom si routování trochu představili, podíváme se na (z prstu vycucaný) příklad. Máme dvě aplikace, jedna loguje klasicky do souboru, druhá posílá logované události přes HTTP. Obojí chceme publikovat do Elasticsearche, ale události přes HTTP chceme ještě dále zpracovávat a tak je pošleme navíc do Kafky.
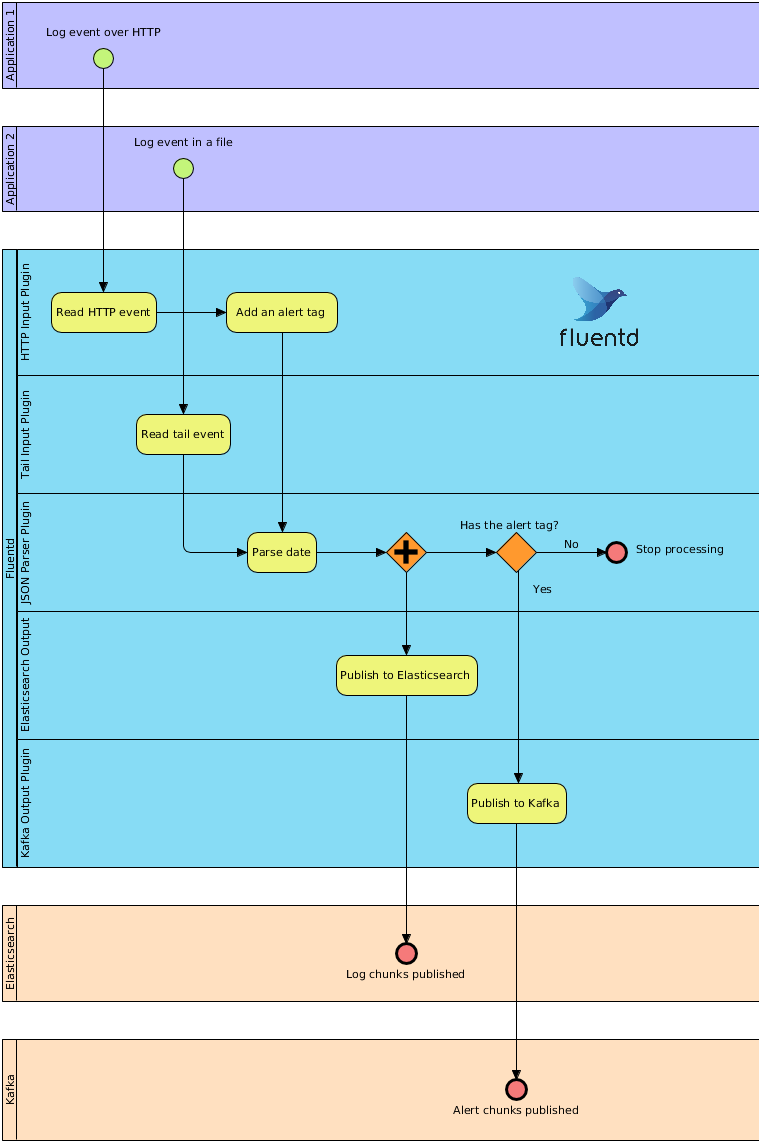
Příklad routování ve Fluentd
Pokračování příště
Zase jednou se mi článek rozrostl víc, než jsem předpokládal, takže ho rozdělím na dva díly. Příště bychom tedy zakončili dvěma tématy:
- Jednoduchý příklad emulující ELK
- Reálný use case